
There are situations that we deal with short text, probably messy, without a lot of training data. In that case, we need external semantic information. Instead of using the conventional bag-of-words (BOW) model, we should employ word-embedding models, such as Word2Vec, GloVe etc.
Suppose we want to perform supervised learning, with three subjects, described by the following Python dictionary:
classdict={'mathematics': ['linear algebra',
'topology',
'algebra',
'calculus',
'variational calculus',
'functional field',
'real analysis',
'complex analysis',
'differential equation',
'statistics',
'statistical optimization',
'probability',
'stochastic calculus',
'numerical analysis',
'differential geometry'],
'physics': ['renormalization',
'classical mechanics',
'quantum mechanics',
'statistical mechanics',
'functional field',
'path integral',
'quantum field theory',
'electrodynamics',
'condensed matter',
'particle physics',
'topological solitons',
'astrophysics',
'spontaneous symmetry breaking',
'atomic molecular and optical physics',
'quantum chaos'],
'theology': ['divine providence',
'soteriology',
'anthropology',
'pneumatology',
'Christology',
'Holy Trinity',
'eschatology',
'scripture',
'ecclesiology',
'predestination',
'divine degree',
'creedal confessionalism',
'scholasticism',
'prayer',
'eucharist']}
And we implemented Word2Vec here. To add external information, we use a pre-trained Word2Vec model from Google, downloaded here. We can use it with Python package gensim. To load it, enter
from gensim.models import Word2Vec
wvmodel = Word2Vec.load_word2vec_format('<path-to>/GoogleNews-vectors-negative300.bin.gz', binary=True)
How do we represent a phrase in Word2Vec? How do we do the classification? Here I wrote two classes to do it.
Average
We can represent a sentence by summing the word-embedding representations of each word. The class, inside SumWord2VecClassification.py, is coded as follow:
from collections import defaultdict
import numpy as np
from nltk import word_tokenize
from scipy.spatial.distance import cosine
from utils import ModelNotTrainedException
class SumEmbeddedVecClassifier:
def __init__(self, wvmodel, classdict, vecsize=300):
self.wvmodel = wvmodel
self.classdict = classdict
self.vecsize = vecsize
self.trained = False
def train(self):
self.addvec = defaultdict(lambda : np.zeros(self.vecsize))
for classtype in self.classdict:
for shorttext in self.classdict[classtype]:
self.addvec[classtype] += self.shorttext_to_embedvec(shorttext)
self.addvec[classtype] /= np.linalg.norm(self.addvec[classtype])
self.addvec = dict(self.addvec)
self.trained = True
def shorttext_to_embedvec(self, shorttext):
vec = np.zeros(self.vecsize)
tokens = word_tokenize(shorttext)
for token in tokens:
if token in self.wvmodel:
vec += self.wvmodel[token]
norm = np.linalg.norm(vec)
if norm!=0:
vec /= np.linalg.norm(vec)
return vec
def score(self, shorttext):
if not self.trained:
raise ModelNotTrainedException()
vec = self.shorttext_to_embedvec(shorttext)
scoredict = {}
for classtype in self.addvec:
try:
scoredict[classtype] = 1 - cosine(vec, self.addvec[classtype])
except ValueError:
scoredict[classtype] = np.nan
return scoredict
Here the exception ModelNotTrainedException is just an exception raised if the model has not been trained yet, but scoring function was called by the user. (Codes listed in my Github repository.) The similarity will be calculated by cosine similarity.
Such an implementation is easy to understand and carry out. It is good enough for a lot of application. However, it has the problem that it does not take the relation between words or word order into account.
Convolutional Neural Network
To tackle the problem of word relations, we have to use deeper neural networks. Yoon Kim published a well cited paper regarding this in EMNLP in 2014, titled “Convolutional Neural Networks for Sentence Classification.” The model architecture is as follow: (taken from his paper)
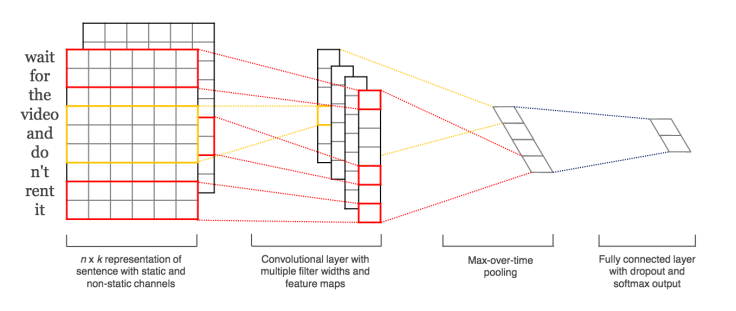
Each word is represented by an embedded vector, but neighboring words are related through the convolutional matrix. And MaxPooling and a dense neural network were implemented afterwards. His paper involves multiple filters with variable window sizes / spatial extent, but for our cases of short phrases, I just use one window of size 2 (similar to dealing with bigram). While Kim implemented using Theano (see his Github repository), I implemented using keras with Theano backend. The codes, inside CNNEmbedVecClassification.py, are as follow:
import numpy as np
from keras.layers import Convolution1D, MaxPooling1D, Flatten, Dense
from keras.models import Sequential
from nltk import word_tokenize
from utils import ModelNotTrainedException
class CNNEmbeddedVecClassifier:
def __init__(self,
wvmodel,
classdict,
n_gram,
vecsize=300,
nb_filters=1200,
maxlen=15):
self.wvmodel = wvmodel
self.classdict = classdict
self.n_gram = n_gram
self.vecsize = vecsize
self.nb_filters = nb_filters
self.maxlen = maxlen
self.trained = False
def convert_trainingdata_matrix(self):
classlabels = self.classdict.keys()
lblidx_dict = dict(zip(classlabels, range(len(classlabels))))
# tokenize the words, and determine the word length
phrases = []
indices = []
for label in classlabels:
for shorttext in self.classdict[label]:
category_bucket = [0]*len(classlabels)
category_bucket[lblidx_dict[label]] = 1
indices.append(category_bucket)
phrases.append(word_tokenize(shorttext))
# store embedded vectors
train_embedvec = np.zeros(shape=(len(phrases), self.maxlen, self.vecsize))
for i in range(len(phrases)):
for j in range(min(self.maxlen, len(phrases[i]))):
train_embedvec[i, j] = self.word_to_embedvec(phrases[i][j])
indices = np.array(indices, dtype=np.int)
return classlabels, train_embedvec, indices
def train(self):
# convert classdict to training input vectors
self.classlabels, train_embedvec, indices = self.convert_trainingdata_matrix()
# build the deep neural network model
model = Sequential()
model.add(Convolution1D(nb_filter=self.nb_filters,
filter_length=self.n_gram,
border_mode='valid',
activation='relu',
input_shape=(self.maxlen, self.vecsize)))
model.add(MaxPooling1D(pool_length=self.maxlen-self.n_gram+1))
model.add(Flatten())
model.add(Dense(len(self.classlabels), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
# train the model
model.fit(train_embedvec, indices)
# flag switch
self.model = model
self.trained = True
def word_to_embedvec(self, word):
return self.wvmodel[word] if word in self.wvmodel else np.zeros(self.vecsize)
def shorttext_to_matrix(self, shorttext):
tokens = word_tokenize(shorttext)
matrix = np.zeros((self.maxlen, self.vecsize))
for i in range(min(self.maxlen, len(tokens))):
matrix[i] = self.word_to_embedvec(tokens[i])
return matrix
def score(self, shorttext):
if not self.trained:
raise ModelNotTrainedException()
# retrieve vector
matrix = np.array([self.shorttext_to_matrix(shorttext)])
# classification using the neural network
predictions = self.model.predict(matrix)
# wrangle output result
scoredict = {}
for idx, classlabel in zip(range(len(self.classlabels)), self.classlabels):
scoredict[classlabel] = predictions[0][idx]
return scoredict
The output is a vector of length equal to the number of class labels, 3 in our example. The elements of the output vector add up to one, indicating its score, and a nature of probability.
Evaluation
A simple cross-validation to the example data set does not tell a difference between the two algorithms:
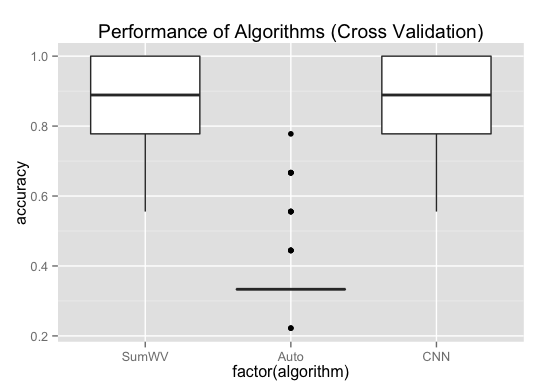
However, we can test the algorithm with a few examples:
Example 1: “renormalization”
- Average: {‘mathematics’: 0.54135105096749336, ‘physics’: 0.63665460856632494, ‘theology’: 0.31014049736087901}
- CNN: {‘mathematics’: 0.093827009201049805, ‘physics’: 0.85451591014862061, ‘theology’: 0.051657050848007202}
As renormalization was a strong word in the training data, it gives an easy result. CNN can distinguish much more clearly.
Example 2: “salvation”
- Average: {‘mathematics’: 0.14939650156482298, ‘physics’: 0.21692765541184023, ‘theology’: 0.5698233329716329}
- CNN: {‘mathematics’: 0.012395491823554039, ‘physics’: 0.022725773975253105, ‘theology’: 0.96487873792648315}
“Salvation” is not found in the training data, but it is closely related to “soteriology,” which means the doctrine of salvation. So it correctly identifies it with theology.
Example 3: “coffee”
- Average: {‘mathematics’: 0.096820211601723272, ‘physics’: 0.081567332119268032, ‘theology’: 0.15962682945135631}
- CNN: {‘mathematics’: 0.27321341633796692, ‘physics’: 0.1950736939907074, ‘theology’: 0.53171288967132568}
Coffee is not related to all subjects. The first architecture correctly indicates the fact, but CNN, with its probabilistic nature, has to roughly equally distribute it (but not so well.)
The code can be found in my Github repository: stephenhky/PyShortTextCategorization. (This repository has been updated since this article was published. The link shows the version of the code when this appeared online.)
- Kwan-Yuet Ho, “Word-Embedding Algorithms,” Everything About Data Analytics, WordPress (2016). [WordPress]
- Google Code: Word2Vec. [Google Code]
- gensim: topic modeling for human. [link]
- Github: stephenhky/PyShortTextCategorization. (Oct 12, 2016) [Github]
- Yoon Kim, “Convolutional Neural Networks for Sentence Classification,” EMNLP 2014, 1746-1751. (arXiv:1408.5882) [arXiv]
- “cs231n: Convolutional Neural Networks for Visual Recognition: Architeture Overview,” Stanford University. [link]
- keras: deep learning library for Theano and Tensorflow. [link]
- Github: yoonkim/CNN_sentence. [Github]
- Kwan-Yuet Ho, “Probabilistic Theory of Word Embeddings: GloVe,” Everything About Data Analytics, WordPress (2016). [WordPress]
- Kwan-Yuet Ho, “Toying with Word2Vec,” Everything About Data Analytics, WordPress (2015). [WordPress]
- Radim Řehůřek, “Making sense of word2vec,” RaRe Technologies (2014). [link]
- Wikipedia: Convolutional Neural Network. [Wikipedia]

The codes here are not up to Keras 2 standard. For a newer version of the code, please refer to my Github repository: stephenhky/PyShortTextCategorization
LikeLike
When I try to implement it I got the following error:
Using TensorFlow backend.
/usr/local/lib/python3.5/dist-packages/pandas/core/computation/__init__.py:18: UserWarning: The installed version of numexpr 2.4.3 is not supported in pandas and will be not be used
The minimum supported version is 2.4.6
ver=ver, min_ver=_MIN_NUMEXPR_VERSION), UserWarning)
File “/usr/local/lib/python3.5/dist-packages/stemming/porter.py”, line 176
print stem(“fundamentally”)
^
SyntaxError: invalid syntax
LikeLike
the code runs in Python 2.7. When it comes to Python >3, this print statement is invalid
and currently Keras is updated to >2, and they have a new set of layers. Please go to the Github repository for the implementation of this algorithm: https://github.com/stephenhky/PyShortTextCategorization
LikeLike
Thanks @stephenhky . Is there any suggestions to improve the accuracy of classification ?
LikeLike
Hi. Could you please explain how do we use Keras? I am now and do not understand what a back end is.
LikeLike
Keras can use TensorFlow / Theano / CNTK as the backend.
An implementation of Keras is here:
https://github.com/stephenhky/PyShortTextCategorization/blob/master/shorttext/classifiers/embed/nnlib/frameworks.py
LikeLike
To improve the accuracy of the classification, there are a few ways:
1. a better-fit pre-processing, which fits to your works case;
2. more training data;
3. some case you may want to train your own embedding model.
LikeLike
Only wanna remark on few general things, The website layout is perfect, the written content is real superb. “The reason there are two senators for each state is so that one can be the designated driver.” by Jay Leno.
LikeLike
Good work.
1. Does it really deep neural network? what I see is only 3 layers.
2. How about dropout rate & l2 constraint ?
3. Why you set number of filter =1200?
LikeLike
1. Your observation is correct. But this framework is flexible to include deep neural network
2. I usually just use the default drop out or reg rate= 0.0, but you can set it: https://github.com/stephenhky/PyShortTextCategorization/blob/master/shorttext/classifiers/embed/nnlib/frameworks.py
3. No particular reason
LikeLike
Which model is this in your newer github repository. I do not see anything in the newer version called CNNEmbedVecClassification.py
LikeLike
In my newer version, I make all the models, which are keras models that can be put into a classifier instance. See: http://shorttext.readthedocs.io/en/latest/tutorial_nnlib.html
VarNNEmbeddedVecClassifier is the classifier class, and CNNWordEmbed is the ConvNet model in this case.
LikeLike
Thanks, related to the page you linked to, should there be a “frameworks” submodule in the shorttext/classifier module? I don’t see one. I see only “embed” and “bow” here: https://github.com/stephenhky/PyShortTextCategorization/tree/master/shorttext/classifiers
(I have not yet successfully installed the package on my machine because of a problem with one of the dependencies, so I’m relying on git-hub browsing for now.)
LikeLike
there is a file __init__.py that defines framework module, and from that you can see it is under the package embed.
if you use pip and invoking -U in the command line, it should install all the dependencies for you. would you let me know what the dependency issues are? (you can also report to my issue page om github.)
LikeLike
Ok, so why would you represent a sentence as a sum of word embeddings?
This maybe works for very short sentences, but in general it sounds weird to me. Why should the sum or an average be a good representation for a sentence? Or did I miss something?
LikeLike
This is only the first part of this post. The idea is that the sum or average captures the “meaning” of the sentence. In BOW model, it is also the same case.
However, summing them does not capture the correlation or sequences. That’s why in the second part of this post, I mentioned CNN. In fact, we can also use RNN.
LikeLike