
Quantum computing has been picking up the momentum, and there are many startups and scholars discussing quantum machine learning. A basic knowledge of quantum two-level computation ought to be acquired.
Recently, Rigetti, a startup for quantum computing service in Bay Area, published that they opened to public their cloud server for users to simulate the use of quantum instruction language, as described in their blog and their White Paper. It is free.
Go to their homepage, http://rigetti.com/, click on “Get Started,” and fill in your information and e-mail. Then you will be e-mailed keys of your cloud account. Copy the information to a file .pyquil_config, and in your .bash_profile, add a line
export PYQUIL_CONFIG="$HOME/.pyquil_config"
More information can be found in their Installation tutorial. Then install the Python package pyquil, by typing in the command line:
pip install -U pyquil
Some of you may need to root (adding sudo in front).
Then we can go ahead to open Python, or iPython, or Jupyter notebook, to play with it. For the time being, let me play with creating an entangled singlet state, 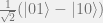
First of all, import all necessary libraries:
import numpy as np from pyquil.quil import Program import pyquil.api as api from pyquil.gates import H, X, Z, CNOT
You can see that the package includes a lot of quantum gates. First, we need to instantiate a quantum simulator:
# starting the quantum simulator quantum_simulator = api.SyncConnection()
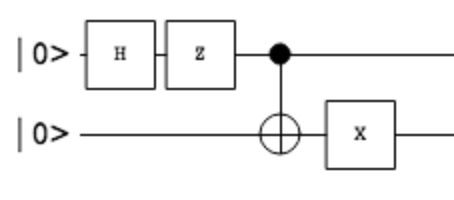
Then we implement the quantum circuit with a “program” as follow:
# generating singlet state # 1. Hadamard gate # 2. Pauli-Z # 3. CNOT # 4. NOT p = Program(H(0), Z(0), CNOT(0, 1), X(1)) wavefunc, _ = quantum_simulator.wavefunction(p)
The last line gives the final wavefunction after running the quantum circuit, or “program.” For the ket, the rightmost qubit is qubit 0, and the left of it is qubit 1, and so on. Therefore, in the first line of the program, H, the Hadamard gate, acts on qubit 0, i.e., the rightmost qubit. Running a simple print statement:
print wavefunc
gives
(-0.7071067812+0j)|01> + (0.7071067812+0j)|10>
The coefficients are complex, and the imaginary part is described by j. You can extract it as a numpy array:
wavefunc.amplitudes
If we want to calculate the metric of entanglement, we can use the Python package pyqentangle, which can be installed by running on the console:
pip install -U pyqentangle
Import them:
from pyqentangle import schmidt_decomposition from pyqentangle.schmidt import bipartitepurestate_reduceddensitymatrix from pyqentangle.metrics import entanglement_entropy, negativity
Because pyqentangle does not recognize the coefficients in the same way as pyquil, but see each element as the coefficients of 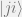
tensorcomp = wavefunc.amplitudes.reshape((2, 2))
Then perform Schmidt decomposition (which the Schmidt modes are actually trivial in this example):
# Schmidt decomposition schmidt_modes = schmidt_decomposition(tensorcomp) for prob, modeA, modeB in schmidt_modes: print prob, ' : ', modeA, ' ', modeB
This outputs:
0.5 : [ 0.+0.j 1.+0.j] [ 1.+0.j 0.+0.j] 0.5 : [-1.+0.j 0.+0.j] [ 0.+0.j 1.+0.j]
Calculate the entanglement entropy and negativity from its reduced density matrix:
print 'Entanglement entropy = ', entanglement_entropy(bipartitepurestate_reduceddensitymatrix(tensorcomp, 0)) print 'Negativity = ', negativity(bipartitepurestate_reduceddensitymatrix(tensorcomp, 0))
which prints:
Entanglement entropy = 0.69314718056 Negativity = -1.11022302463e-16
The calculation can be found in this thesis.
P.S.: The circuit was drawn by using the tool in this website, introduced by the Marco Cezero’s blog post. The corresponding json for the circuit is:
{"gate":[],{"gate":[], "circuit": [{"type":"h", "time":0, "targets":[0], "controls":[]}, {"type":"z", "time":1, "targets":[0], "controls":[]}, {"type":"x", "time":2, "targets":[1], "controls":[0]}, {"type":"x", "time":3, "targets":[1], "controls":[]}], "qubits":2,"input":[0,0]}
Continue reading "A First Glimpse of Rigetti’s Quantum Computing Cloud"

