This is an age of quantification, meaning that we want to give everything, even qualitative, a number. In schools, teachers measure how good their students master mathematics by grading, or scoring their homework. The funding agencies measure how good a scientist is by counting the number of his publications, the citations, and the impact factors. We measure how successful a person is by his annual income. We can question all these approaches of measurement. Yet however good or bad the measures are, we look for a metric to measure.
Original PageRank Algorithm
We measure webpages too. In the early ages of Internet, people performed searching on sites such as Yahoo or AltaVista. The keywords they entered are the main information for the browser to do the searching. However, a big problem was that a large number of low quality or irrelevant webpages showed up in search results. Some were due to malicious manipulation of keyword tricks. Therefore, it gave rise a need to rank the webpages. Larry Page and Sergey Brin, the founders of Google, tackled this problem as a thesis topic in Stanford University. But this got commercialized, and Brin never received his Ph.D. They published their algorithm, called PageRank, named after Larry Page, at the Seventh International World Wide Web Conference (WWW7) in April 1998. [Brin & Page 1998] This algorithm is regarded as one of the top ten algorithms in data mining by a survey paper published in the IEEE International Conference on Data Mining (ICDM) in December 2006. [Wu et. al. 2008]

Larry Page and Sergey Brin (source)
The idea of the PageRank algorithm is very simple. It regards each webpage as a node, and each link in the webpage as a directional edge from the source to the target webpage. This forms a network, or a directed graph, of webpages connected by their links. A link is seen as a vote to the target homepage, and if the source homepage ranks high, it enhances the target homepage’s ranking as well. Mathematically it involves solving a large matrix using Newton-Raphson’s method. (Technologies involving handling the large matrix led to the MapReduce programming paradigm, another big data trend nowadays.)

Example (made by Python with packages networkx and matplotlib)
Let’s have an intuition through an example. In the network, we can easily see that “Big Data 1” has the highest rank because it has the most edges pointing to it. However, there are pages such as “Big Data Fake 1,” which looks like a big data page, but in fact it points to “Porn 1.” After running the PageRank algorithm, it does not have a high rank. The sample of the output is:
[('Big Data 1', 0.00038399273501500979),
('Artificial Intelligence', 0.00034612564364377323),
('Deep Learning 1', 0.00034221161094691966),
('Machine Learning 1', 0.00034177713235138173),
('Porn 1', 0.00033859136614724074),
('Big Data 2', 0.00033182629176238337),
('Spark', 0.0003305912073357307),
('Hadoop', 0.00032928389859040422),
('Dow-Jones 1', 0.00032368956852396916),
('Big Data 3', 0.00030969537721207128),
('Porn 2', 0.00030969537721207128),
('Big Data Fake 1', 0.00030735245262038724),
('Dow-Jones 2', 0.00030461420169420618),
('Machine Learning 2', 0.0003011838672138951),
('Deep Learning 2', 0.00029899313444392865),
('Econophysics', 0.00029810944592071552),
('Big Data Fake 2', 0.00029248837867043803),
('Wall Street', 0.00029248837867043803),
('Deep Learning 3', 0.00029248837867043803)]
You can see those pornographic webpages that pretend to be big data webpages do not have rank as high as those authentic ones. PageRank fights against spam and irrelevant webpages. Google later further improved the algorithm to combat more advanced tricks of spam pages.
You can refer other details in various sources and textbooks. [Rajaraman and Ullman 2011, Wu et. al. 2008]
Use in Social Media and Forums
Mathematically, the PageRank algorithm deals with a directional graph. As one can imagine, any systems that can be modeled as directional graph allow rooms for applying the PageRank algorithm. One extension of PageRank is ExpertiseRank.
Jun Zhang, Mark Ackerman and Lada Adamic published a conference paper in the International World Wide Web (WWW7) in May 2007. [Zhang, Ackerman & Adamic 2007] They investigated into a Java forum, by connecting users to posts and anyone replying to it as a directional graph. With an algorithm closely resembled PageRank, they found the experts and influential people in the forum.

Graphs in ExpertiseRank (take from [Zhang, Ackerman & Adamic 2007])
There are other algorithms like HITS (Hypertext induced topic selection) that does similar things. And social media such as Quora (and its Chinese counterpart, Zhihu) applied a link analysis algorithm (probabilistic topic network, see this.) to perform topic network building. Similar ideas are also applied to identify high-quality content in Yahoo! Answers. [Agichtein, Castillo, Donato, Gionis & Mishne 2008]
Use in Finance and Econophysics
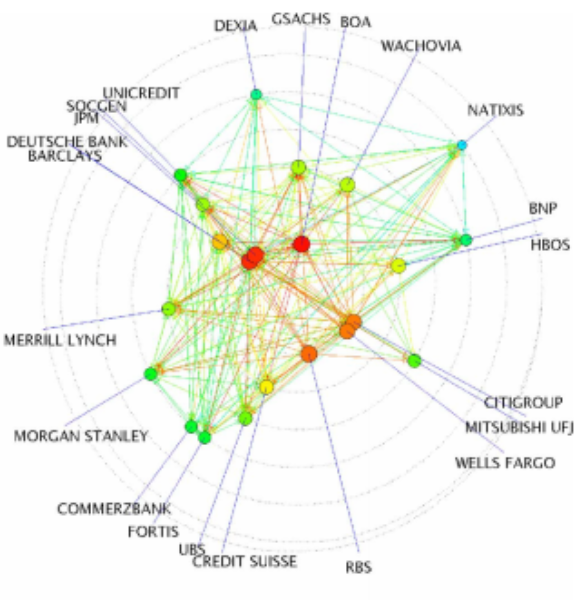
PageRank algorithm is also applied outside information technology fields. Financial engineers and econophysicists applied an algorithm, called DebtRank, which is very similar to PageRank, to determine the systemically important financial institutions in a financial network. This work is published in Nature Scientific Reports. [Battiston, Puliga, Kaushik, Tasca & Caldarelli 2012] In their study, each node represents a financial institution, and a directional edge means the estimated potential impact of an institution to another one. Using DebtRank, we are able to identify the centrally important institutions that potentially impacted other institutions in the network once a financial crisis occurs.

DebtRank network, taken from [Battiston, Puliga, Kaushik, Tasca & Caldarelli 2012])
Continue reading “Ranking Everything: an Overview of Link Analysis Using PageRank Algorithm” →

, where
and
are the nodes (vertices) and edges respectively.
describes how nodes are connected:
if there is an edge connecting from node
to node
, and
otherwise.
is another way to describe how nodes are connected:
if a node
is a diagonal matrix, with elements
denotes the number of neighbors for node
, and the normalized graph Laplacian is
.
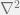
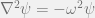

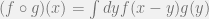


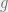








 (Taken from
(Taken from