
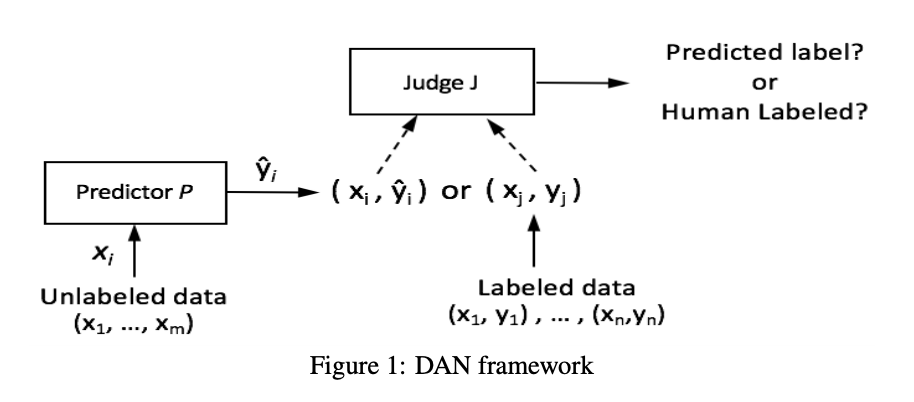
In 2019, Google published a new Python library called “tensornetwork” (arXiv:1905.01330) that facilitates the computation of… tensor networks. Tensor network is a tool from quantum many-body theory, widely used in condensed matter physics. There have been a lot of numerical packages for tensor computation, but this library takes it to the next level because of its distinctive framework.
What is a tensor network, though?
“A tensor network is a collection of tensors with indices connected according to a network pattern. It can be used to efficiently represent a many-body wave-function in an otherwise exponentially large Hilbert space.”
https://www.perimeterinstitute.ca/research/research-initiatives/tensor-networks-initiative
Renormalization Group (RG)
It is not until recently that tensor networks have its application in machine learning. As stated in a previous post, a mathematical connection between restricted Boltzmann machine (RBM) and variational renormalization group (RG) was drawn. (arXiv:1410.1831) It shedded light to the understanding of interpretability of deep learning, which has been criticized to be a black box. However, RBM is just a type of unsupervised machine learning, but how about others?
Seeing this, Schwab, one of the authors of the RG paper, and Stoudenmire did some work to realize the use of RG in machine learning. Stoudenmore is a physicist, and he made use of density matrix renormalization group (DMRG) that he is familiar with, and invented a supervised learning algorithm, which is later renamed tensor network machine learning (TNML). The training is adapted from the sweeping algorithm, the standard of DMRG, that combining bipartite site one-by-one, updating it, and decomposing into two site by studying its quantum entanglment (using singular value decomposition, or Schmidt decomposition).

Instead of bringing interpretability to deep learning, this work in fact opened a new path of new machine learning algorithms with known techniques.
What is RG?
Renormalization group (RG) is a formalism of “zooming out” in scale-invariant system, determining which terms to truncate in a model. It is an important formalism in high energy physics and statistical field theory. (See Ma’s book for reference.)
Density matrix renormalization group (RG) is a variational real-space numerical technique that look at collections of quantum bits (zoomed-out) as a block. It was invented by Steven White, and it is useful in studying strongly correlated electronic systems. (PRL 69 (19): 2863-2866 (1992)). However, the original DMRG paper is not very accessible, until it is rephrased using the tensor network notation (TNN), as shown in Schollwoeck’s article.
Is Tensor Network Related to Quantum Computing?
This is not an easy question to answer. Tensor networks come from quantum physics, but quantum physics is usually not directly leading to quantum computing. In fact, classical computing hardwares have a lot of quantum physics in it. A simple answer to this question is no, as the algorithm using tensor network is implemented in classical computers.
There have been a lot of publications on quantum machine learning lately. A classic book on this topic is written by Peter Wittek. The book covers topics on basic machine learning and quantum computing, and then quantum machine learning algorithms. There is a quantum counterpart of each of the common machine learning algorithms in the book. However, we know it would be much more useful if there are new algorithms exploiting the advantages of quantum computing. Tensor network is a natural choice as it builds on qubits, and the representations and operations are naturally quantum.
Next…
Tensor network is an interesting subject from both a theoretical and applicational perspective. In coming posts I will talk about its application on machine learning and a taste of codes.
- Github: google/TensorNetwork. [Github] [RTFD]
- Chase Roberts, Ashley Milsted, Martin Ganahl, Adam Zalcman, Bruce Fontaine, Yijian Zou, Jack Hidary, Guifre Vidal, Stefan Leichenauer, “TensorNetwork: A Library for Physics and Machine Learning,” arXiv:1905.01330 (2019). [arXiv]
- “Google TensorNetwork Library Dramatically Accelerates ML & Physics Tasks,” Syncedreview. (2019) [Medium]
- Chase Roberts, “Introducing TensorNetwork, an Open Source Library for Efficient Tensor Calculations,” Google AI Blog. (2019) [GoogleAIBlog]
- “Tensor Networks and Density Matrix Renormalization Group,” Everything About Data Analytics. (2016) [WordPress]
- P. Mehta, D. J. Schwab, “An exact mapping between the Variational Renormalization Group and Deep Learning,” arXiv:1410.3831 (2014). [arXiv]
- Sheng-kang Ma, Modern Theory of Critical Phenomena, (New York, NY: Routledge, 2018). [Amazon]
- S. R. White, “Density matrix formulation for quantum renormalization groups,” Phys. Rev. Lett. 69, 2863 (1992). [APS]
- Ulrich Schollwoeck, “The density-matrix renormalization group,” Rev. Mod. Phys. 77, 259 (2005); arXiv:cond-mat/0409292. [arXiv]
- Ulrich Schollwoeck, “The density-matrix renormalization group in the age of matrix product states,” Annals of Physics 326, 96 (2011); arXiv:1008.3477. [arXiv]
- Peter Wittek, Quantum Machine Learning: What Quantum Computing Means to Data Mining (San Diego, CA: Academic Press, 2014). [Amazon] [PDF
 ]
] - Jacob Biamonte, Peter Wittek, Nicola Pancotti, Patrick Rebentrost, Nathan Wiebe, Seth Lloyd, “Quantum Machine Learning,” Nature 549, 195-202 (2017). [Nature]
- Tensor Networks: From Entangled Quantum Matter to Emergent Space Time, Perimeter Institute. [Perimeter]
Feature picture taken from Perimeter Institute.




 , instead of computing it directly by
, instead of computing it directly by  , it approximates the filter in terms of Chebyshev polynomial:
, it approximates the filter in terms of Chebyshev polynomial: ,
, are the Chebyshev polynomials. It has been proved by Hammond et. al. that by well truncating this representation, Chebyshev polynomials are very good to approximate the function. Then the convolution is:
are the Chebyshev polynomials. It has been proved by Hammond et. al. that by well truncating this representation, Chebyshev polynomials are very good to approximate the function. Then the convolution is: .
.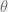 ’s are the parameters to be trained. This fixed the bases of the representation, and it speeds up computation. The disadvantage is that eigenvalues are clusters in a few values with large gaps.
’s are the parameters to be trained. This fixed the bases of the representation, and it speeds up computation. The disadvantage is that eigenvalues are clusters in a few values with large gaps. ,
, to complex unit half-circle. Instead of Chebyshev polynomials, it approximates the filter as:
to complex unit half-circle. Instead of Chebyshev polynomials, it approximates the filter as:![g(\lambda) = c_0 + \sum_{j=1}^r \left[ c_j C^j (h \lambda) + c_j^{\ast} C^{j \ast} (h \lambda) \right]](https://s0.wp.com/latex.php?latex=g%28%5Clambda%29+%3D+c_0+%2B+%5Csum_%7Bj%3D1%7D%5Er+%5Cleft%5B+c_j+C%5Ej+%28h+%5Clambda%29+%2B+c_j%5E%7B%5Cast%7D+C%5E%7Bj+%5Cast%7D+%28h+%5Clambda%29+%5Cright%5D+&bg=f1f1f1&fg=666666&s=0&c=20201002) ,
,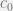 is real and other
is real and other  ’s are generally complex, and
’s are generally complex, and 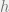 is a zoom parameter, and
is a zoom parameter, and 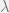 ’s are the eigenvalues of the graph Laplacian. Tuning $h$ makes one find the best zoom that spread the top eigenvalues.
’s are the eigenvalues of the graph Laplacian. Tuning $h$ makes one find the best zoom that spread the top eigenvalues.  ‘s are computed by training. This solves the problem of unfavorable clusters in ChebNet.
‘s are computed by training. This solves the problem of unfavorable clusters in ChebNet.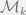 , with elements
, with elements  being the number of motifs in the graph the the edge
being the number of motifs in the graph the the edge 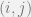 that it belongs to.
that it belongs to.
 .
.
 , where
, where  and
and  are the nodes (vertices) and edges respectively.
are the nodes (vertices) and edges respectively. describes how nodes are connected:
describes how nodes are connected:  if there is an edge connecting from node
if there is an edge connecting from node 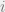 to node
to node  , and
, and 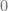 otherwise.
otherwise.  is another way to describe how nodes are connected:
is another way to describe how nodes are connected:  if a node
if a node 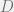 is a diagonal matrix, with elements
is a diagonal matrix, with elements  denotes the number of neighbors for node
denotes the number of neighbors for node  , and the normalized graph Laplacian is
, and the normalized graph Laplacian is  .
.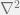 . The reader can easily verify this by constructing a graph of 2D lattice and compute the graph Laplacian matrix, and find that it is the same as the discretized Laplacian operator.
. The reader can easily verify this by constructing a graph of 2D lattice and compute the graph Laplacian matrix, and find that it is the same as the discretized Laplacian operator.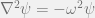 ,
, . In graph convolutional neural network, as Bruna et. al. suggested in 2013, the graph is calculated in the graph Fourier space, instead of directly dealing with the Laplacian matrix in all layers of network.
. In graph convolutional neural network, as Bruna et. al. suggested in 2013, the graph is calculated in the graph Fourier space, instead of directly dealing with the Laplacian matrix in all layers of network.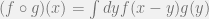 ,
, .
. and
and  , with
, with  being the unitary eigenmatrix,
being the unitary eigenmatrix, .
.






{kind=link}