It has been a while since I wrote about topological data analysis (TDA). For pedagogical reasons, a lot of the codes were demonstrated in the Github repository PyTDA. However, it is not modularized as a package, and those codes run in Python 2.7 only.
Upon a few inquiries, I decided to release the codes as a PyPI package, and I named it mogutda, under the MIT license. It is open-source, and the codes can be found at the Github repository MoguTDA. It runs in Python 2.7, 3.5, and 3.6.
For more information and simple tutorial, please refer to the documentation, or the Github page.
Michael Kosterlitz, Duncan Haldane, and David J. Thouless are the laureates of Nobel Prize in Physics 2016, “for theoretical discoveries of topological phase transitions and topological phases of matter.” Before Thouless, topology was not known to the physics community. It is a basic knowledge nowadays, however.
I am particularly familiar with Berezinskii-Kosterlitz-Thouless phase transition. What is it? Before that, phase transitions had been studied through the framework of spontaneous symmetry breaking, employing the tools in functional field theory and renormalization group. Matter can be in either disordered state that the symmetry is not broken, or ordered state that a particular continuous symmetry is broken. Near the critical point, many observables found to exhibit long-range order, with , which are so universal that all physical systems described by the same Landau-Ginzburg-Wilson (LGW) model are found to obey it. But in lower dimensions such as d=2, proved by Mermin, Wagner, and Hohenberg, an ordered state is not stable because of its huge fluctuation.
The absence of an ordered state does not exclude the possibility of a phase transition. Berezinskii in 1971, and Kosterlitz and Thouless in 1973, suggested a phase transition that concerns the proliferation of topological objects. While the correlation must be short-ranged, i.e., , a normal description using LGW model in d=2 does not permit that, unless vortices are considered. However, below a certain temperature, due to energy configuration, it is better for these vortices to be bounded. Then the material exhibits quasi-long-range order, i.e., . This change in correlation function is a phase transition different from that induced by spontaneous symmetry breaking, but the proliferation of isolated topological solitons.
Their work started the study of topology in condensed matter system. Not long after this work, there was the study of topological defects in various condensed matter system, and then fractional quantum Hall effect, topological insulators, topological quantum computing, A phase in liquid crystals and helimagnets etc. “Topological” is the buzzword in condensed matter physics community nowadays. Recently, there is a preprint article connecting machine learning and topological physical state. (See: arXiv:1609.09060.)
In machine learning, deep learning is the buzzword. However, to understand how these things work, we may need a theory, or we may need to construct our own features if a large amount of data are not available. Then, topological data analysis (TDA) becomes important in the same way as condensed matter physics.
Topology has been shown to reveal important information about geometry and shape from data, [Carlsson 2015][Carlsson 2009] as I have talked about in various TDA blog entries. I have also demonstrated how to describe the topology if discrete data points by constructing simplicial complexes, and then calculated the homology and Betti numbers. (I will talk about persistent homology in the future.) Dealing with discrete data points in our digital storage devices, homology is the best way to describe it.
But if you are from a physics background, you may be familiar with the concept of homotopy and fundamental group. Some physicists deal with topology without digging into advanced mathematical tools but simply through solitons. There is a well-written introduction in this blog. In the physical world, an object is said to be topological if:
there is a singular point that cannot be removed by a continuous deformation of field; [Mermin 1979]
it has a saddle-point equation of the model that is different from another object of another topology, [Rajaraman 1987] inducing different kinds of physical dynamics; [Bray 1994]
it can only be removed by crossing an energy barrier, which can be described by an instanton; [Calzetta, Ho, Hu 2010]
it can proliferate through Kosterlitz-Thouless (BKT) phase transition; [Kosterliz, Thouless 1973]
it can form in a system through a second-order phase transition at a finite rate, a process known as Kibble-Zurek mechanism (KZM); [Kibble 1976] [Zurek 1985] and
its topology can be described by a winding number. (c.f. Betti numbers in homology)
Topological objects include vortices in magnets, superfluids, superconductors, or Skyrmions in helimagnets. [Mühlbauer et. al. 2009] [Ho et. al. 2010] They may come in honeycomb order, like Abrikosov vortices in type-II superconductors, [Abrikosov 1957] and helical nanofilaments in smectics. [Matsumoto et. al. 2009] It is widely used in fractional quantum Hall effect [Tsui et. al. 1982] and topological insulators (a lot of references can be found…). They can all be described using homotopy and winding numbers. We can see that topology is useful to describe the physical world for the complexities and patterns. There are ideas in string-net theory to use topology to describe the emergence of patterns and new phases of quantum matter. [Zeng et. al. 2015] Of course, I must not omit topological quantum computing that makes the qubits immune to environmental noise. [Das Sarma, Freedman, Nayak 2005]
A-phase of helimagnet (MnSi) (taken from [Ho et. al. 2010]
However in data analytics, we do not use homotopy, albeit its beauty and usefulness in the physical world. Here are some of the reasons:
In using homotopy, sometimes it takes decades for a lot of brains to figure out which homotopy groups to use. But in data analysis, we want to grasp the topology simply from data.
Homotopy deals with continuous mappings, but data are discrete. Simplicial homology captures it more easily.
In a physical system, we deal with usually one type of homotopy groups. But in data, we often deal with various topologies which we are not aware of in advance. Betti numbers can describe the topology easily by looking at data.
Of course, homotopy is difficult to compute numerically.
Afra Zomorodian argued the use of homology over homotopy in his book as well. [Zomorodian 2009]
We have been talking about the elements of topological data analysis. In my previous post, I introduced simplicial complexes, concerning the ways to connect points together. In topology, it is the shape and geometry, not distances, which matter ( although while constructing the distance does play a role).
With the simplicial complexes, we can go ahead to describe its topology. We will use the techniques in algebraic topology without going into too much details. The techniques involves homology, but a full explanation of it requires the concepts of normal subgroup, kernel, image, quotient group in group theory. I will not talk about them, although I admit that there is no easy ways to talk about computational topology without touching them. I highly recommend the readers can refer to Zomorodian’s textbook for more details. [Zomorodian 2009]
I will continue with the Python class
SimplicialComplex
that I wrote in the previous blog post. Suppose we have an k-simplex, then the n-th face is any combinations with n+1 vertices. A simplicial complex is such that a face contained in a face is also a face of the complex. In this, we can define the boundary operator by
,
where indicates the i-th vertex be removed. This operator gives all the boundary faces of a face . The faces being operated are k-faces, and this operator will be mapped to a (k-1)-faces. Then the boundary operator can be seen as a -matrix, where is the number of k-faces. This can be easily calculated with the following method:
class SimplicialComplex:
...
def boundary_operator(self, i):
source_simplices = self.n_faces(i)
target_simplices = self.n_faces(i-1)
if len(target_simplices)==0:
S = dok_matrix((1, len(source_simplices)), dtype=np.float32)
S[0, 0:len(source_simplices)] = 1
else:
source_simplices_dict = {}
for j in range(len(source_simplices)):
source_simplices_dict[source_simplices[j]] = j
target_simplices_dict = {}
for i in range(len(target_simplices)):
target_simplices_dict[target_simplices[i]] = i
S = dok_matrix((len(target_simplices), len(source_simplices)), dtype=np.float32)
for source_simplex in source_simplices:
for a in range(len(source_simplex)):
target_simplex = source_simplex[:a]+source_simplex[(a+1):]
i = target_simplices_dict[target_simplex]
j = source_simplices_dict[source_simplex]
S[i, j] = -1 if a % 2==1 else 1 # S[i, j] = (-1)**a
return S
With the boundary operator, we can calculate the Betti numbers that characterize uniquely the topology of the shapes. Actually it involves the concept of homology groups that we are going to omit. To calculate the k-th Betti numbers, we calculate:
.
By rank-nullity theorem, [Jackson]
the Betti number is then
where the rank of the image of an operator can be easily computed using the rank method available in numpy. Then the method of calculating the Betti number is
If we draw a simplicial complex on a 2-dimensional plane, we almost have , and . $\beta_0$ indicates the number of components, the number of bases for a tunnel, and the number of voids.
Let’s have some examples. Suppose we have a triangle, not filled.
On top of the techniques in this current post, we can describe the homology of discrete points using persistent homology, which I will describe in my future posts. I will probably spend a post on homotopy in comparison to other types of quantitative problems.
Topology has been around for centuries, but it did not catch the attention of many data analysts until recently. In an article published in Nature Scientific Reports, the authors demonstrated the power of topology in data analysis through examples including gene expression from breast rumors, voting data in the United States, and player performance data from the NBA. [Lum et. al. 2013]
As an introduction, they described topological methods “as a geometric approach to pattern or shape recognition within data.” It is true that in machine learning, we never care enough pattern recognition, but topology adds insights regarding the shapes of data that do not change with continuous deformation. For example, a circle and an ellipse have “the same topology.” The distances between data points are not as important as the shape. Traditional machine learning methods deal with feature vectors, distances, or classifications, but the topology of the data is usually discarded. Gunnar Carlsson demonstrated in a blog that a thin ellipse of data may be misrepresented as two straight parallel lines or one straight lines. [Carlsson 2015] Dimensionality reduction algorithms such as principal component analysis (PCA) often disregard the topology as well. (I heard that Kohenen’s self-organizing maps (SOM) [Kohonen 2000] retain the topology of higher dimensional data during the dimensionality reduction, but I am not confident enough to say that.)
Euler introduced the concept of topology in the 18th century. Topology has been a big subject in physics since 1950s. The string theory, as one of the many efforts in unifying gravity and other three fundamental forces, employs topological dimensions. In condensed matter physics, the fractional quantum Hall effect is a topological quantum effect. There are topological solitons [Rajaraman 1987] such as quantum vortices in superfluids, [Simula, Blakie 2006; Calzetta, Ho, Hu 2010] columns of topological solitons (believed to be Skyrmions) in helical magnets, [Mühlbauer et. al. 2009; Ho et. al. 2010; Ho 2012] hexagonal solitonic objects in smectic liquid crystals [Matsumoto et. al. 2009]… When a field becomes sophisticated, it becomes quantitative; when a quantitative field becomes sophisticated, it requires abstract mathematics such as topology for a general description. I believe analysis on any kinds of data is no exception.
There are some good reviews and readings about topological data analysis (TDA) out there, for example, the ones by Gunnar Carlsson [Carlsson 2009] and Afra Zomorodian [Zomorodian 2011]. While physicists talk about homotopy, data analysts talk about persistent homology as it is easier to compute. Data have to be described in a simplicial complex or a graph/network. Then the homology can be computed and represented in various ways such as barcodes. [Ghrist 2008] Then we extract insights about the data from it.
Topology has a steep learning curve. I am also a starter learning about this. This blog entry will not be the last talking about TDA. Therefore, I opened a new session called TDA for all of my blog entries about it. Let’s start the journey!
There is an R package called “TDA” that facilitates topological data analysis. [Fasy et. al. 2014] A taste of homology of a simplicial complex is also demonstrated in a Wolfram demo.


 , which are so universal that all physical systems described by the same Landau-Ginzburg-Wilson (LGW) model are found to obey it. But in lower dimensions such as d=2, proved by Mermin, Wagner, and Hohenberg, an ordered state is not stable because of its huge fluctuation.
, which are so universal that all physical systems described by the same Landau-Ginzburg-Wilson (LGW) model are found to obey it. But in lower dimensions such as d=2, proved by Mermin, Wagner, and Hohenberg, an ordered state is not stable because of its huge fluctuation. , a normal description using LGW model in d=2 does not permit that, unless vortices are considered. However, below a certain temperature, due to energy configuration, it is better for these vortices to be bounded. Then the material exhibits quasi-long-range order, i.e.,
, a normal description using LGW model in d=2 does not permit that, unless vortices are considered. However, below a certain temperature, due to energy configuration, it is better for these vortices to be bounded. Then the material exhibits quasi-long-range order, i.e.,  . This change in correlation function is a phase transition different from that induced by spontaneous symmetry breaking, but the proliferation of isolated topological solitons.
. This change in correlation function is a phase transition different from that induced by spontaneous symmetry breaking, but the proliferation of isolated topological solitons.


![\partial_k \sigma = \sum_i (-1)^i [v_0 v_1 \ldots \hat{v}_i \ldots v_k]](https://s0.wp.com/latex.php?latex=%5Cpartial_k+%5Csigma+%3D+%5Csum_i+%28-1%29%5Ei+%5Bv_0+v_1+%5Cldots+%5Chat%7Bv%7D_i+%5Cldots+v_k%5D&bg=f1f1f1&fg=666666&s=0&c=20201002) ,
, indicates the i-th vertex be removed. This operator gives all the boundary faces of a face
indicates the i-th vertex be removed. This operator gives all the boundary faces of a face 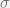 . The faces being operated are k-faces, and this operator will be mapped to a (k-1)-faces. Then the boundary operator can be seen as a
. The faces being operated are k-faces, and this operator will be mapped to a (k-1)-faces. Then the boundary operator can be seen as a  -matrix, where
-matrix, where 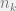 is the number of k-faces. This can be easily calculated with the following method:
is the number of k-faces. This can be easily calculated with the following method: .
.

 ,
,  and
and  . $\beta_0$ indicates the number of components,
. $\beta_0$ indicates the number of components, 


