
Entropy is one of the most fascinating ideas in the history of mathematical sciences.
In Phenomenological Thermodynamics…
Entropy was introduced into thermodynamics in the 19th century. Like the free energies, it describes the state of a thermodynamic system. At the beginning, entropy is merely phenomenological. The physicists found it useful to incorporate the description using entropy in the second law of thermodynamics with clarity and simplicity, instead of describing it as convoluted heat flow (which is what it is originally about) among macroscopic systems (say, the heat flow from the hotter pot of water to the air of the room). It did not carry any statistical meaning at all until 1870s.
In Statistical Physics…

Ludwig Boltzmann (1844-1906)
The statistical meaning of entropy was developed by Ludwig Boltzmann, a pioneer of statistical physics, who studied the connection of the macroscopic thermodynamic behavior to the microscopic components of the system. For example, he described the temperature to be the average of the fluctuating kinetic energy of the particles. And he formulated the entropy to be

where i is the label for each microstate, and 
Information Theory and Statistical Physics United
In statistical physics, Boltzmann’s assumption of equal a priori equilibrium properties is an important assumption. However, in 1957, E. T. Jaynes published a paper relating information theory and statistical physics in Physical Review indicating that merely the principle of maximum entropy is sufficient to describe equilibrium statistical system. [Jaynes 1957] In statistical physics, we are aware that systems can be described as canonical ensemble, or a softmax function (normalized exponential), i.e., 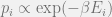


under the constraints


where E is a constant. The softmax distribution can be obtained by this simple optimization problem, using basic variational calculus (Euler-Lagrange equation) and Lagrange’s multipliers.
The principle of maximum entropy can be found in statistics too. For example, the form of Gaussian distribution can be obtained by maximizing the entropy

with the knowledge of the mean 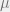




In any statistical systems, the probability distributions can be computed with the principle of maximum entropy, as Jaynes put it [Jaynes 1957]
It is the least biased estimate possible on the given information; i.e., it is maximally noncommittal with regard to missing information.
In statistical physics, entropy is roughly a measure how “chaotic” a system is. In information theory, entropy is a measure how surprising the information is. The smaller the entropy is, the more surprising the information is. And it assumes no additional information. Without constraints other than the normalization, the probability distribution is that all 
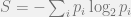
which is different from the thermodynamic entropy by the constant 
Entropy in Natural Language Processing (NLP)
The principle of maximum entropy assumes nothing other than the given information to compute the most optimized probability distribution, which makes it a desirable algorithm in machine learning. It can be regarded as a supervised learning algorithm, with the features being 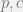


Does it really assume no additional information? No. The way you construct the features is how you add information. But once the features are defined, the calculation depends on the training data only.
The classifier based on maximum entropy has found its application in part-of-speech (POS) tagging, machine translation (ML), speech recognition, and text mining. A good review was written by Berger and Della Pietra’s. [Berger, Della Pietra, Della Pietra 1996] A lot of open-source softwares provide maximum entropy classifiers, such as Python NLTK and Apache OpenNLP.
In Quantum Computation…
One last word, entropy is used to describe quantum entanglement. A composite bipartite quantum system is said to be entangled if its subsystems must be described in a mixed state, i.e., it must be statistical if one of the subsystems is only considered. Then the entanglement entropy is given by [Nielssen, Chuang 2011]
which is essentially the same formula. The more entangled the system is, the larger the entanglement entropy. However, composite quantum systems tend to decrease their entropy over time though.
- E. T. Jaynes, “Information Theory and Statistical Mechanics”, Phys. Rev. 106, 620 (1957).
- L. N. Hoang, “Shannon’s Information Theory“, Science4All (2013).
- A. L. Berger, S. A. Della Pietra, V. J. Della Pietra, “A Maximum Entropy Approach to Natural Language Processing”, Computational Linguistics 22, 39-71 (1996).
- C. D. Manning, H. Schütze, “Foundations of Statistical Natural Language Processing“, MIT Press (1999).
- Stanford Natural Language Processing by Coursera.
- R. K. Pathria, “Statistical Mechanics” (2nd ed.), Butterworth-Heinemann (1996).
- M. L. Nielssen, I. Chuang, “Quantum Computation and Quantum Information“, Cambridge (2011).
