
One fascinating application of deep learning is the training of a model that outputs vectors representing words. A project written in Google, named Word2Vec, is one of the best tools regarding this. The vector representation captures the word contexts and relationships among words. This tool has been changing the landscape of natural language processing (NLP).
Let’s have some demonstration. To use Word2Vec in Python, you need to have the package gensim installed. (Installation instruction: here) And you have to download a trained model (GoogleNews-vectors-negative300.bin.gz), which is 3.6 GB big!! When you get into a Python shell (e.g., IPython), type
from gensim.models.word2vec import Word2Vec
model = Word2Vec.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
This model enables the user to extract vector representation of length 300 of an English word. So what is so special about this vector representation from the traditional bag-of-words representation? First, the representation is standard. Once trained, we can use it in future training or testing dataset. Second, it captures the context of the word in a way that the algebraic operation of these vectors has meanings.
Here I give 5 examples.
A Juvenile Cat
What is a juvenile cat? We know that a juvenile dog is a puppy. Then we can get it by carry out the algebraic calculation 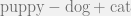
model.most_similar(positive=['puppy', 'cat'], negative=['dog'], topn=5)
This outputs:
[(u'kitten', 0.7634989619255066), (u'puppies', 0.7110899686813354), (u'pup', 0.6929495334625244), (u'kittens', 0.6888389587402344), (u'cats', 0.6796488761901855)]
which indicates that “kitten” is the answer (correctly!) The numbers are similarities of these words with the vector representation
from scipy.spatial import distance print (1-distance.cosine(model['kitten'], model['puppy']+model['cat']-model['dog']))
which outputs 0.763498957413.

This demonstration shows that in the model, 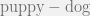
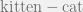
Capital of Taiwan
Where is the capital of Taiwan? We can find it if we know the capital of another country. For example, we know that Beijing is the capital of China. Then we can run the following:
model.most_similar(positive=['Beijing', 'Taiwan'], negative=['China'], topn=5)
which outputs
[(u'Taipei', 0.7866502404212952), (u'Taiwanese', 0.6805002093315125), (u'Kaohsiung', 0.6034111976623535), (u'Chen', 0.5905819535255432), (u'Seoul', 0.5865181684494019)]
Obviously, the answer is “Taipei.” And interestingly, the model sees Taiwan in the same footing of China!
 Taipei (taken from Airasia: http://www.airasia.com/mo/en/destinations/taipei.page)
Taipei (taken from Airasia: http://www.airasia.com/mo/en/destinations/taipei.page)
Past Participle of “eat”
We can extract grammatical information too. We know that the past participle of “go” is “gone”. With this, we can find that of “eat” by running:
model.most_similar(positive=[‘gone’, ‘eat’], negative=[‘go’], topn=5)
which outputs:
[(u'eaten', 0.7462186217308044), (u'eating', 0.6516293287277222), (u'ate', 0.6457351446151733), (u'overeaten', 0.5853317975997925), (u'eats', 0.5830586552619934)]
Capital of the State of Maryland
However, this model does not always work. If it can find the capital of Taiwan, can it find those for any states in the United States? We know that the capital of California is Sacramento. How about Maryland? Let’s run:
model.most_similar(positive=['Sacramento', 'Maryland'], negative=['California'], topn=5)
which sadly outputs:
[(u'Towson', 0.7032245397567749), (u'Baltimore', 0.6951349973678589), (u'Hagerstown', 0.6367553472518921), (u'Anne_Arundel', 0.5931429266929626), (u'Oxon_Hill', 0.5879474878311157)]
But the correct answer should be Annapolis!
 Downtown Annapolis (taken from Wikipedia)
Downtown Annapolis (taken from Wikipedia)

More About Word2Vec
Word2Vec was developed by Tomáš Mikolov. He previously worked for Microsoft Research. However, he switched to Google, and published a few influential works on Word2Vec. [Mikolov, Yih, Zweig 2013] [Mikolov, Sutskever, Chen, Corrado, Dean 2013] [Mikolov, Chen, Corrado, Dean 2013] Their conference paper in 2013 can be found on arXiv. He later published a follow-up work on a package called Doc2Vec that considers phrases. [Le, Mikolov 2014]
Earlier this year, I listened to a talk in DCNLP meetup spoken by Michael Czerny on his award-winning blog entry titled “Modern Methods for Sentiment Analysis.” He applied the vector representations of words by Word2Vec to perform sentiment analysis, assuming that similar sentiments cluster together in the vector space. (He took averages of the vectors in tweets to extract emotions.) [Czerny 2015] I highly recommend you to read his blog entry. On the other hand, Xin Rong wrote an explanation about how Word2Vec works too. [Rong 2014]
There seems to be no progress on the project Word2Vec anymore as Tomáš Mikolov no longer works in Google. However, the Stanford NLP Group recognized that Word2Vec captures the relations between words in their vector representation. They worked on a similar project, called GloVe (Global Vectors), which tackles the problem with matrix factorization. [Pennington, Socher, Manning 2014] Radim Řehůřek did some analysis comparing Word2Vec and GloVe. [Řehůřek 2014] GloVe can be implemented in Python too.
- Google Project: Word2Vec
- Python package: gensim: topic modeling for humans
- Google Scholar Citation: Tomáš Mikolov
- T. Mikolov, W. Yih, G. Zweig, “Linguistic Regularities in Continuous Space Word Representations”, HLT-NAACL, 746-751 (2013).
- T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, J. Dean, “Distributed representations of words and phrases and their compositionality”, Advances in neural information processing systems, 3111-3119 (2013).
- T. Mikolov, K. Chen, G. Corrado, J. Dean, “Efficient Estimation of Word Representations in Vector Space”, Proceedings of Workshop at ICLR (2013). [arXiv:1301.3781]
- Q. V. Le, T. Mikolov, “Distributed representations of sentences and documents” (2014). [arXiv:1405.4053]
- DCNLP (Twitter: DCNLP)
- M. Czerny, “Modern Methods for Sentiment Analysis“, District Data Labs (2015).
- X. Rong, “word2vec Parameter Learning Explained”, arXiv:1411.2738 (2014).
- J. Pennington, R. Socher, C. D. Manning, “GloVe: Global Vectors for Word Representation”, Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014). [link, pdf]
- Radim Řehůřek, “Making sense of word2vec“, RaRe Technologies (2014).
- foldl: A GloVe implementation in Python
- K.-Y. Ho, “BirdView (6) – Talking Not So Deep About Deep Learning“, WordPress (2015).
