
The topic of word embedding algorithms has been one of the interests of this blog, as in this entry, with Word2Vec [Mikilov et. al. 2013] as one of the main examples. It is a great tool for text mining, (for example, see [Czerny 2015],) as it reduces the dimensions needed (compared to bag-of-words model). As an algorithm borrowed from computer vision, a lot of these algorithms use deep learning methods to train the model, while it was not exactly sure why it works. Despite that, there are many articles talking about how to train the model. [Goldberg & Levy 2014, Rong 2014 etc.] Addition and subtraction of the word vectors show amazing relationships that carry semantic values, as I have shown in my previous blog entry. [Ho 2015]
However, Tomas Mikolov is no longer working in Google, making the development of this algorithm discontinued. As a follow-up of their work, Stanford NLP group later proposed a model, called GloVe (Global Vectors), that embeds word vectors using probabilistic methods. [Pennington, Socher & Manning 2014] It can be implemented in the package glove-python in python, and text2vec in R (or see their CRAN post). Their paper is neatly written, and a highly recommended read.
To explain the theory of GloVe, we start with some basic probabilistic picture in basic natural language processing (NLP). We suppose the relation between the words occur in certain text windows within a corpus, but the details are not important here. Assume that 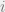




where 


The tilde means “context,” but we will later assume it is also a word. Citing the example from their paper, take
And the addition and subtraction in Word2Vec is similar to this. We want the ratio to be like the subtraction as in Word2Vec (and multiplication as in addition), then we should modify the function 

On the other hand, the input arguments of

In NLP, the word-word co-occurrence matrices are symmetric, and our function

where we define,

It is clear that

As a result of this equation, the authors defined the following cost function to optimize for GloVe model:

where 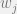



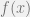
As Radim Řehůřek said in his blog entry, [Řehůřek 2014] it is a neat paper, but their evaluation is crappy.
This theory explained why certain similar relations can be achieved, such as Paris – France is roughly equal to Beijing – China, as both can be transformed to the ratio in the definition of
It is a neat paper, as it employs optimization theory and probability theory, without any dark box deep learning.
- K.-Y. Ho, “Word Embedding Algorithms,” WordPress (2016).
- K.-Y. Ho, “Toying with Word2Vec,” WordPress (2015).
- T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, J. Dean, “Distributed representations of words and phrases and their compositionality,” Advances in neural information processing systems, 3111-3119 (2013).
- Google Project: Word2Vec
- Y. Goldberg, O. Levy, “word2vec Explained: deriving Mikolov et al.’s negative-sampling word-embedding method,” arXiv:1402.3722 (2014).
- X. Rong, “word2vec Parameter Learning Explained,” arXiv:1411.2738 (2014).
- M. Czerny, “Modern Methods for Sentiment Analysis“, District Data Labs (2015).
- GloVe: Global Vectors for Word Representation.
- glove-python package.
- CRAN: text2vec. (GloVe Word Embeddings)
- TextMiner, “Getting Started with Word2Vec and GloVe in Python,” TextMiningOnline (2015).
- J. Pennington, R. Socher, C. D. Manning, “GloVe: Global Vectors for Word Representation,” Empirical Methods in Natural Language Processing (EMNLP), pp. 1532-1543 (2014). [PDF]
- R. Řehůřek, “Making sense of word2vec“, RaRe Technologies (2014).
- K.-Y. Ho, “LDA2Vec: a hybrid of LDA and Word2Vec,” WordPress (2016).
- K.-Y. Ho, “Local and Global: Words and Topics,” WordPress (2016).

Hi, thank you for this nice article !
You conclude saying “It is a neat paper, as it employs optimization theory and probability theory, without any dark box deep learning.”. Which algorithm do you refer to? Because I know Word2vec is said to be shallow, not deep.
Also, would you say that GloVe is more probabilistic than Word2vec? If yes, why? How does it help GloVe perform better?
Thank you so much !
LikeLike
For the conclusion, I refer to the GloVe paper as the neat paper. If you go through the paper, there are no neural networks involved, and the cost function can be described using probability theory. The explanation is clear.
Yes, Word2Vec is a shallow networks.
If by probabilistic you mean the algorithm being stochastic, I would agree that quite likely the gradient optimization is a stochastic one; If you mean it is a theory derived from Bayesian probability, I would agree too. But from what I know, it performs as good as Word2Vec.
LikeLike
We first require F is be a homomorphism,
F((w_i – w_j)^T \tilde{w}_k) = \frac{F(w_i^T \tilde{w}_k) }{ F(w_j^T \tilde{w}_k)} (*)
Hi I don’t understand this one, can you explain more detailed about Why we have to require F be a homomorphism between such 2 groups (R, +) and (R>0, X)? Also why from this equation:
F( (w_i – w_j)^T \tilde{w}_k) = \frac{P_{ik}}{P_{jk}}.
we can derive above equation (*) ?
Thank you so much
LikeLike
We first require F is be a homomorphism,
F((w_i – w_j)^T \tilde{w}_k) = \frac{F(w_i^T \tilde{w}_k) }{ F(w_j^T \tilde{w}_k)} (*)
Hi I don’t understand this one, can you explain more detailed about Why we have to require F be a homomorphism between such 2 groups (R, +) and (R>0, X)? Also why from this equation:
F( (w_i – w_j)^T \tilde{w}_k) = \frac{P_{ik}}{P_{jk}}.
we can derive above equation (*) ?
Thank you so much
LikeLike
Thank you for your question. Because we want the function to be invariant under relabeling, we want it to be a homomorphism. Then why should it be multiplication instead of addition? I think it is because of the context (k in the equation), which we want to be cancelled out while relabeling i and j.
LikeLike
Can you provide the example with some words data?
LikeLike